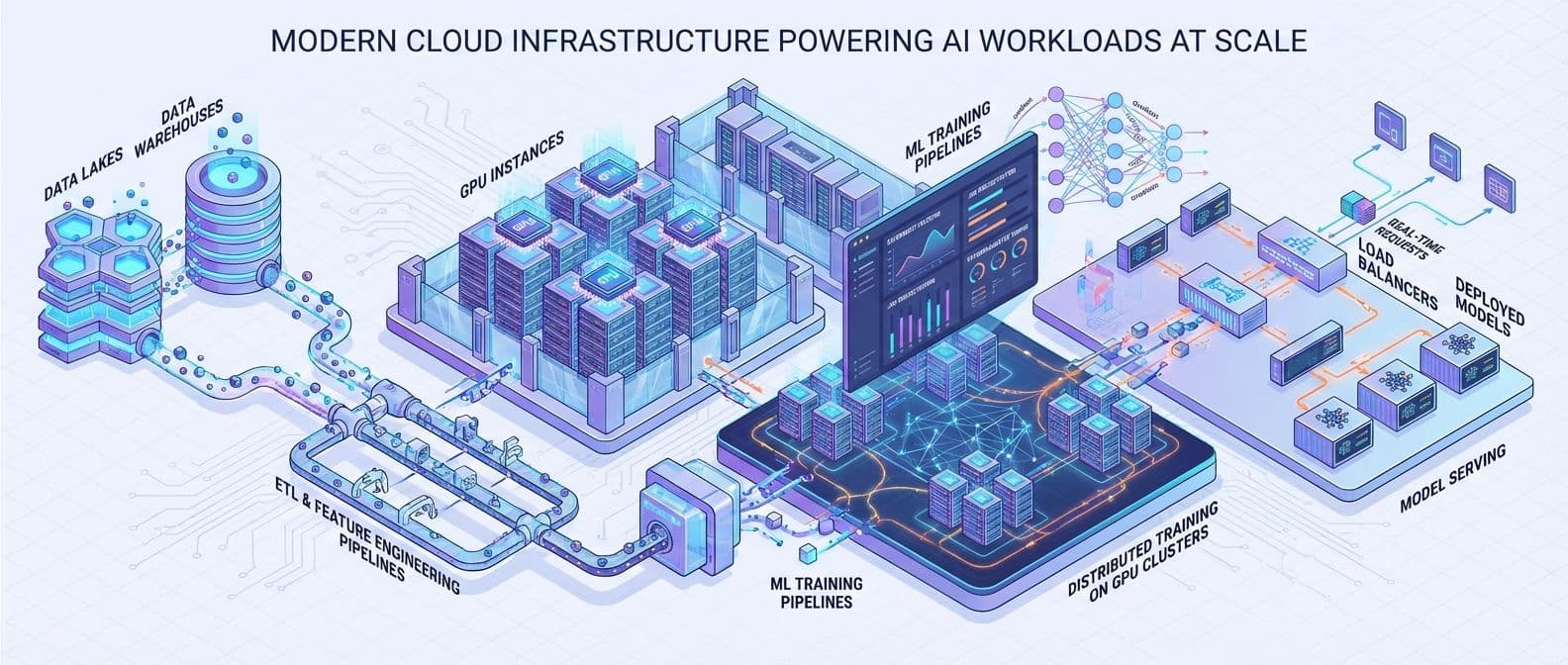
Here’s a concise, skimmable summary of the article:
Deploying AI in production is fundamentally different from traditional web apps. AI workloads are:
- Compute-heavy (especially GPUs)
- Data-intensive (complex pipelines, large volumes)
- Experiment-driven (models, data, and configs change frequently)
- Highly variable in load (spiky inference traffic)
- Expensive (GPU and storage costs can explode without control)
These constraints drive every architectural choice—from compute and storage to deployment and monitoring.
Core idea: Choose the right GPU/compute strategy; it’s your biggest cost and performance lever.
- Use GPU instances for deep learning (A100/H100-class for training, cheaper GPUs or even CPU for optimized inference).
- Consider:
- GPU memory (LLMs often need 40GB+; may require multi-GPU)
- Interconnect (NVLink for distributed training)
- Spot instances for cheaper, interruptible training
- Regional availability and capacity reservations for production
- For inference, right-size aggressively; a model trained on A100 may serve fine on T4/CPU with quantization.
- Managed ML platforms (SageMaker, Azure ML, Vertex AI) simplify infra at the cost of flexibility and price.
Core idea: AI is a data problem first; architecture determines what you can train and serve.
- Use a data lake (S3/GCS/Blob) as the raw data foundation.
- Process with distributed engines (Spark, Dask) and expose features via a feature store.
- Feature stores provide:
- Consistent features across training and inference
- Reuse across teams
- Point-in-time correctness (no leakage)
- Low-latency online serving
- Implement data versioning (DVC, lakeFS) to reproduce experiments and debug.
- Use vector databases (Pinecone, Weaviate, Milvus, pgvector) for embeddings, semantic search, and RAG.
Core idea: Balance speed, cost, and reproducibility.
- Use distributed training when models or data are too large:
- Data parallelism (simpler; same model, different data)
- Model parallelism (for models that don’t fit on one GPU)
- Experiment tracking (MLflow, W&B, Neptune) is mandatory:
- Log hyperparameters, metrics, artifacts
- Compare runs, manage model registry and stages
- Orchestrate training pipelines (Kubeflow, Airflow, Prefect) for multi-step workflows.
- Implement checkpointing and fault tolerance to survive preemptions and failures.
Core idea: Match serving pattern to latency and throughput needs.
- Real-time inference (sub-second, synchronous):
- Keep large models warm; manage load time
- Use dynamic batching for GPU utilization
- Scale horizontally; consider GPU sharing
- Cache repeat predictions when possible
- Batch inference for offline scoring (recommendations, risk scores).
- Streaming inference for event-driven, stateful use cases (fraud, anomalies).
- Edge inference for ultra-low latency, offline, or privacy-constrained scenarios.
Core idea: Treat models like software, but account for data and drift.
A typical model CI/CD pipeline:
- Code commit
- Unit tests (data + model code)
- Training on representative subset
- Evaluation vs baseline
- Validation (drift, bias checks)
- Deployment to staging → production
- Monitoring and feedback
Use A/B tests and canaries to de-risk rollouts.
Monitor for:
- Data drift and concept drift
- Accuracy and business KPIs
- Latency and throughput
- Resource utilization (GPU, memory)
Core idea: AI systems often handle sensitive data and high-impact decisions.
- Data protection: encryption at rest/in transit, VPC isolation, least-privilege IAM, auditing.
- Model security:
- Guard against model extraction, adversarial inputs, data poisoning, prompt injection.
- Compliance: design for HIPAA, SOX, PCI-DSS, GDPR, CCPA as needed.
- Explainability: SHAP, LIME, and model cards to document behavior, limits, and risks.
Core idea: Control GPU and storage costs with deliberate design.
- Right-size instances based on real utilization; use auto-scaling.
- Use spot instances for training with robust checkpointing.
- Optimize models:
- Quantization (FP32 → FP16/INT8)
- Pruning
- Distillation (smaller student models)
- Compilation (TensorRT, ONNX Runtime, etc.)
- Use reserved capacity/Savings Plans for stable, predictable workloads.
Typical production AI stack:
| Layer | Components (examples) |
|---|
| Data Ingestion | Kafka, Kinesis, Airflow, Step Functions |
| Data Storage | S3/GCS, Snowflake, BigQuery, feature store |
| Training | SageMaker, Vertex AI, or Kubernetes with GPU nodes |
| Model Registry | MLflow, SageMaker Model Registry, Vertex AI Registry |
| Serving | SageMaker endpoints, KServe, Spark/Dataflow for batch |
| Monitoring | Prometheus/Grafana, cloud-native + ML-specific tools |
| Orchestration | Kubeflow, Airflow, Step Functions |
Start simple, then harden and optimize:
- Prototype with managed services.
- Establish latency, throughput, and cost baselines.
- Add MLOps incrementally: experiment tracking → CI/CD → monitoring.
- Optimize only when real usage justifies it.
- Gradually build shared platform capabilities and self-service tooling.
| Aspect | Recommendation |
|---|
| Compute | Start with managed services; move to custom infra as needs clarify |
| Data | Invest early in feature stores and data versioning |
| Training | Track experiments from day one |
| Serving | Choose serving pattern by latency and scale requirements |
| MLOps | Automate the path from code to production |
| Security | Design for compliance and security upfront |
| Cost | Monitor continuously; optimize based on real usage |
Overall: build flexible, observable, cost-aware AI infrastructure that enables teams to move fast while staying reliable and compliant.